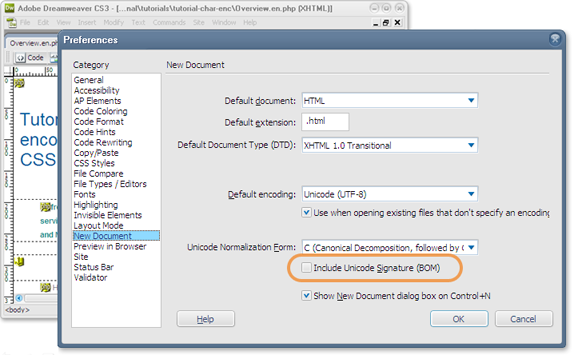
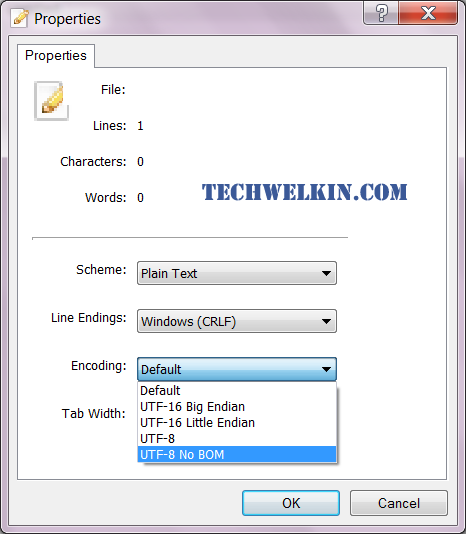
Byte Order Mark (or BOM) is a signal that tells the computer how the bytes are ordered in a Unicode document. Because Unicode can be used in the formats of 8, 16 and 32 bits –it is important for the computer to understand which encoding has been used in the Unicode document. BOM tells exactly the same to the computer. BOM is actually a “zero-width non-breaking space” (practically a NULL character) and it is represented as U+FEFF In HTML code the BOM character can also appear as Just open the file in vim text editor use the “nobomb” command When faced with the bom character problem, many webpage developers try setting encoding of their page to “charset=utf-8” through meta property. But doing this does not mean that you will not face the BOM problem. If a BOM character is causing problems in your HTML display -the problem actually lies in the text editor and not in your HTML/CSS code. Most HTML editors, like Dreamweaver, Programmer’s Notepad, TextPad etc., do provide a way to disable BOM. The option usually appears in the place where you set the encoding of your text editor. It may appear as options like “UTF-8 without BOM” or “UTF-8 No BOM”. Appearance of character in your HTML code can also be solved using the above encoding change in HTML editor. Just set the encoding without BOM and then save the file. Linux commands make it easier to find BOM character and then remove it from files. Powerful Linux tools like grep and shell programming make it a cakewalk. Here is how we can do it: Find the list of files containing BOM characters Remove BOM character So this was it! This is how you can remove bom character from your program/text file. I decided to write this article because I had to waste two hours in learning how to remove the nuisance of ÿþ Unicode 65279 character. Once I learned it, I thought it should be documented so that other programmers can save some time! I hope it was useful for you. Thank you for using TechWelkin.